최근 프로그래머스 SQL 고득점 Kit에서 4~5레벨 위주로 몇 문제를 풀고있습니다.
https://school.programmers.co.kr/learn/courses/30/lessons/301651
오늘 푼 문제 중 하나가 재귀 CTE를 이용하는 쿼리여서 이 참에 정리해보려고 합니다.
데이터베이스에서 계층 구조와 같은 복잡한 데이터를 다룰 때 재귀 쿼리를 사용하면 도움이 될 수 있습니다. 이번 글에서는 SQL의 재귀 쿼리 활용법과 동작 원리, 그리고 NOT IN과 NOT EXISTS를 성능 측면에서 비교해 보겠습니다.
재귀 쿼리란?
재귀 쿼리는 자기 자신을 참조하는 쿼리로, SQL에서는 CTE(Common Table Expression)를 사용하여 작성할 수 있습니다. 주로 다음과 같은 상황에서 유용하게 사용됩니다:
- 조직도와 같은 계층 구조 데이터 탐색
- 그래프 탐색 (경로 찾기, 친구의 친구 찾기 등)
둘 다 대충 느낌이 비슷하죠?
경험상으로는 주로 한 테이블 내에서 같은 테이블 내 컬럼을 참조해야할 때 유용하게 쓰였던 것 같습니다.
재귀 CTE의 기본 구조
재귀 CTE는 다음과 같은 기본 구조를 가집니다:
WITH RECURSIVE [CTE 참조할 이름] AS (
-- 앵커 멤버(기본 케이스)
SELECT col1, col2, col3 ...
FROM table
WHERE [condition]
UNION ALL
-- 재귀 멤버(재귀 케이스)
SELECT col1, col2, col3 ...
FROM table t
JOIN [CTE 참조할 이름] r ON [JOIN_CONDITION]
WHERE [condition]
)
SELECT * FROM [CTE 참조할 이름];- MySQL은 위 처럼
RECURSIVE키워드를 써줘야 합니다. - MS-SQL은 모든 CTE가 기본적으로 재귀 가능이라서 안 써줘도 된다네요.
재귀 쿼리의 동작 원리
재귀 쿼리는 다음과 같은 단계로 실행됩니다:
- 앵커 멤버 실행: 초기 결과 집합 생성
- 재귀 멤버 실행: 이전 단계의 결과를 입력으로 사용
- 반복 실행: 재귀 멤버에서 새로운 행이 더 이상 생성되지 않을 때까지 반복
- 결과 병합: 모든 단계의 결과가 UNION ALL로 합쳐진 결과 반환
실제 문제: 멸종위기의 대장균 찾기
위 문제로 풀어보겠습니다. 문제 설명은 읽고 와주세요.
세대별로 리프 노드를 구하는 문제입니다. 그럼 뭐부터 해야할까요?
네, 세대 정보부터 계산해야 합니다.
현재 세대 정보는 ‘PARENT_ID를 ID로 가진 행의 세대 + 1’ 로 구할 수 있습니다.
어라? 자기 참조하면서 그래프 탐색하듯 구해야겠네요?
네, 재귀로 풀 수 있습니다.
WITH RECURSIVE RECURSIVE_ECOLI AS (
-- 앵커 멤버: 부모가 없는 최초 세포(1세대)
SELECT ID, PARENT_ID, 1 as GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
-- 재귀 멤버: 자식 세포 탐색
SELECT e.ID, e.PARENT_ID, (r.GENERATION + 1) as GENERATION
FROM ECOLI_DATA e
JOIN RECURSIVE_ECOLI r ON e.PARENT_ID = r.ID
)
SELECT COUNT(*) COUNT, GENERATION
FROM RECURSIVE_ECOLI
GROUP BY GENERATION
ORDER BY GENERATION ASC;초기 결과 집합은 부모가 없는 1세대로 시작합니다.
재귀 멤버에서는 이전 단계 결과를 부모로 하는 현재 세대를 구합니다.
자, 이 쿼리는 모든 세포를 세대별로 집계합니다. 그런데 리프 노드(자식이 없는 세포)만 집계하고 싶다면 어떻게 해야 할까요?
따로 필터링이 필요합니다.
리프 노드 필터링: NOT IN vs NOT EXISTS
리프 노드를 식별하는 두 가지 주요 방법을 비교해 보겠습니다.
두 방법 모두 현재 ID가 PARENT_ID 컬럼에 등장하지 않는 경우를 찾습니다.
1. NOT IN 사용
WITH RECURSIVE RECURSIVE_ECOLI AS (
...
)
SELECT COUNT(*) COUNT, GENERATION
FROM RECURSIVE_ECOLI
WHERE ID NOT IN (
SELECT DISTINCT PARENT_ID
FROM ECOLI_DATA
WHERE PARENT_ID IS NOT NULL
)
GROUP BY GENERATION
ORDER BY GENERATION ASC;2. NOT EXISTS 사용
WITH RECURSIVE RECURSIVE_ECOLI AS (
...
)
SELECT COUNT(*) COUNT, GENERATION
FROM RECURSIVE_ECOLI r
WHERE NOT EXISTS (
SELECT 1
FROM ECOLI_DATA e
WHERE e.PARENT_ID = r.ID
)
GROUP BY GENERATION
ORDER BY GENERATION ASC;NOT IN vs NOT EXISTS: 성능 비교
둘 모두 동일한 결과를 내놓습니다. 이 둘의 차이는 뭘까요?
NOT IN의 특징
- 작동 방식: 서브쿼리 결과를 한 번 계산하여 메모리에 저장한 후 비교
- 장점: 서브쿼리가 한 번만 실행됩니다
- 단점NULL 값 처리에 주의 필요 (서브쿼리에 NULL이 있으면 항상 빈 결과 반환)
- 서브쿼리 결과가 큰 경우 메모리 사용량 높음
NOT EXISTS의 특징
- 작동 방식: 상관 서브쿼리로 외부 쿼리의 각 행마다 평가
- 장점:NULL 값 상관 X
- 조건 충족 시 즉시 평가 중단 (단락 평가)
- 단점: 외부 쿼리의 각 행마다 서브쿼리가 실행됩니다 (상관 서브쿼리의 특징)
이 둘을 비교하면
NOT IN이 유리한 상황은
- 서브쿼리 결과가 작고 외부 테이블이 큰 경우
- 서브쿼리에 NULL 값이 없을 때
NOT EXISTS가 유리한 상황은
- 관련 컬럼에 인덱스가 있는 경우
- 외부 테이블의 많은 행이 조건을 만족하는 경우
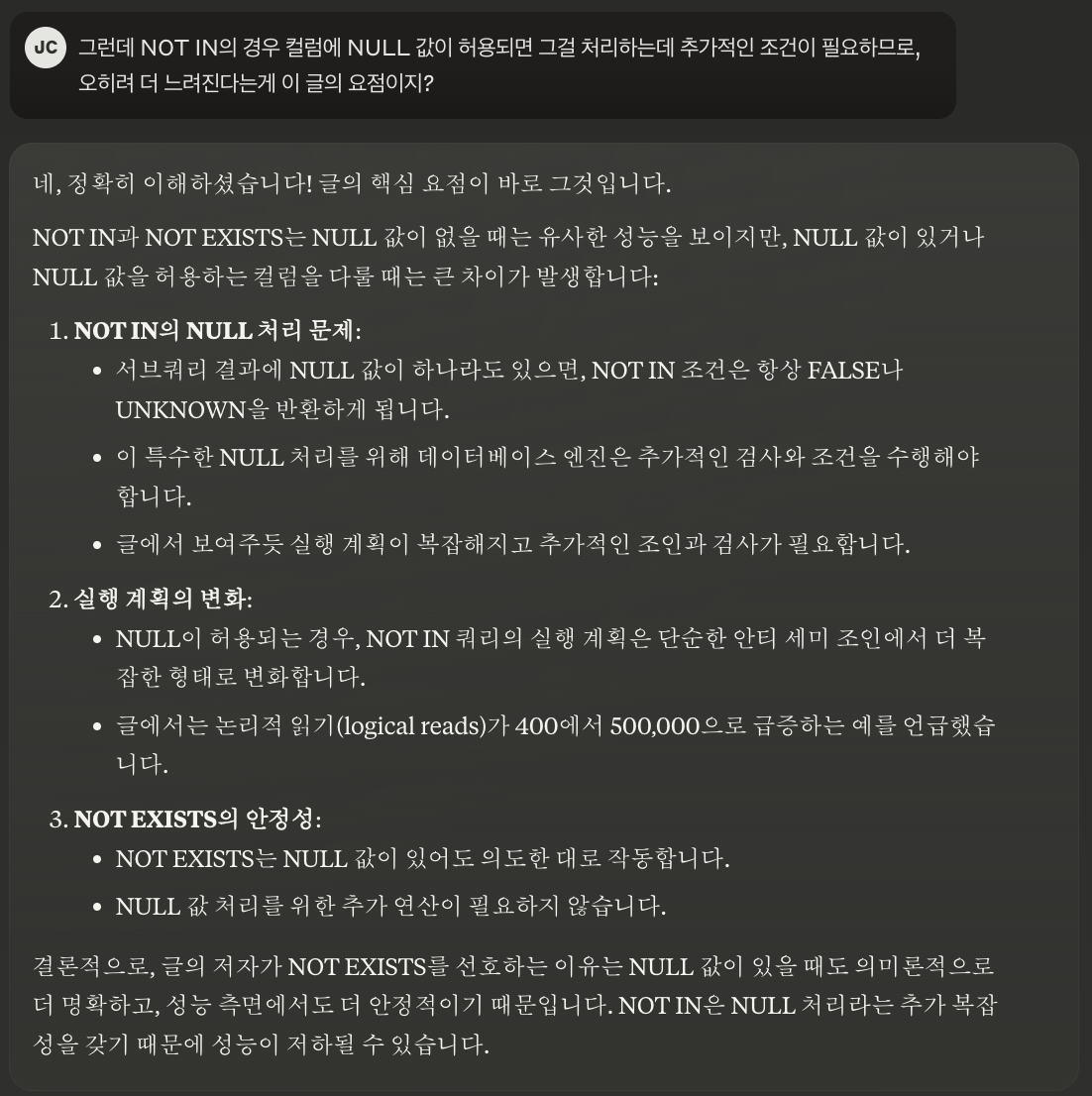
일반적으로 그렇고 저도 그렇게 생각해왔는데, 찾아보니 재밌는 글을 발견했습니다.
https://stackoverflow.com/questions/173041/not-in-vs-not-exists
답변 작성자는 NOT EXISTS가 최적화됨에 따라 실제로는 안티-세미 조인 방식을 사용할 수 있기 때문에 사실상 비슷하고, NOT IN의 경우 NULL 값을 추가로 처리해야되기 때문에 NOT EXISTS가 훨씬 더 빠를 수 있다는 말입니다.
저도 완전히 이해하지는 못 했지만 이 내용을 이해하기 위해 AI(Claude)와 대화한 내용을 공유합니다.



풀이
-- 코드를 작성해주세요
WITH RECURSIVE RECURSIVE_ECOLI AS (
SELECT ID, PARENT_ID, 1 as GENERATION
FROM ECOLI_DATA
WHERE PARENT_ID IS NULL
UNION ALL
SELECT r.ID, r.PARENT_ID, (o.GENERATION + 1) as GENERATION
FROM ECOLI_DATA r
JOIN RECURSIVE_ECOLI o ON o.ID = r.PARENT_ID
)
-- NOT IN
# SELECT COUNT(*) COUNT, GENERATION
# FROM RECURSIVE_ECOLI
# WHERE ID NOT IN (SELECT DISTINCT PARENT_ID FROM ECOLI_DATA WHERE PARENT_ID IS NOT NULL)
# GROUP BY GENERATION
# ORDER BY GENERATION ASC;
-- NOT EXISTS
SELECT COUNT(*) COUNT, GENERATION
FROM RECURSIVE_ECOLI r
WHERE NOT EXISTS (
SELECT 1
FROM ECOLI_DATA e
WHERE e.PARENT_ID = r.ID
)
GROUP BY GENERATION
ORDER BY GENERATION ASC;참고
https://www.geeksforgeeks.org/recursive-cte-in-sql-server/
https://stackoverflow.com/questions/173041/not-in-vs-not-exists
'개발' 카테고리의 다른 글
| Github Actions, Jib와 캐싱을 통해 CI 최적화하기 (0) | 2025.03.21 |
|---|---|
| Mockito 사용 중 @Spy로 실제 객체 동작 활용하기 (0) | 2025.03.10 |
| 속성(Property)과 필드(Field)의 차이 (0) | 2022.11.07 |
| [모바일] Context 선택 (0) | 2022.11.07 |


댓글